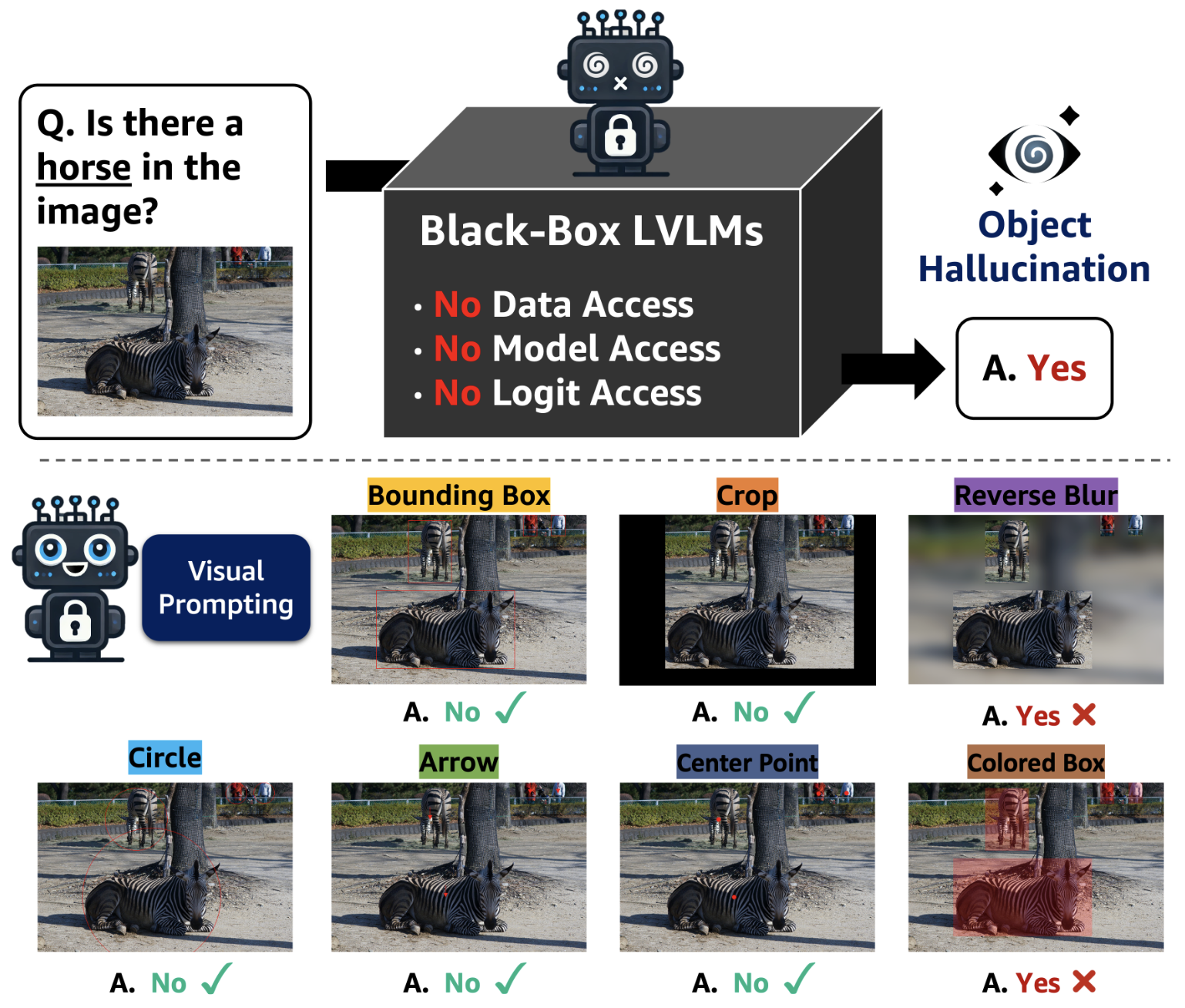
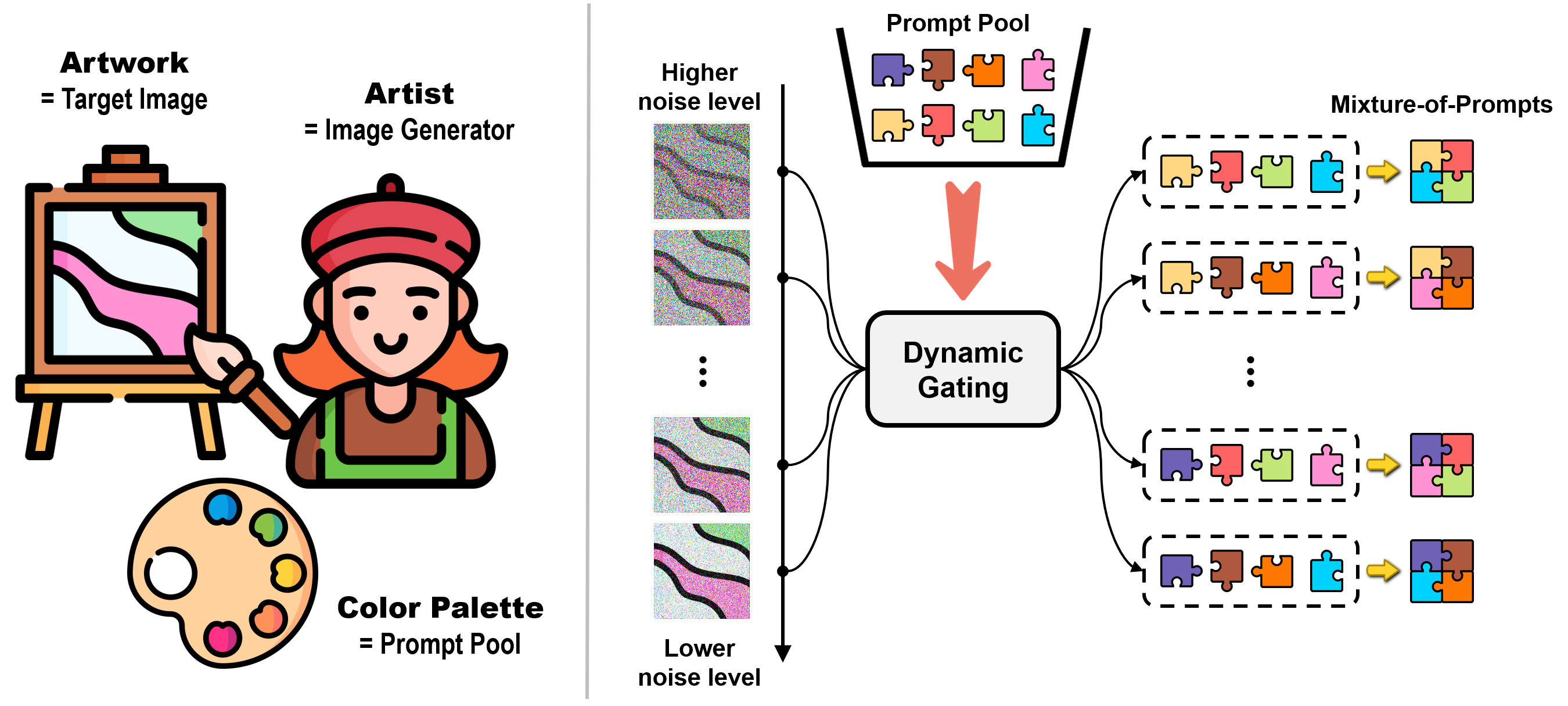
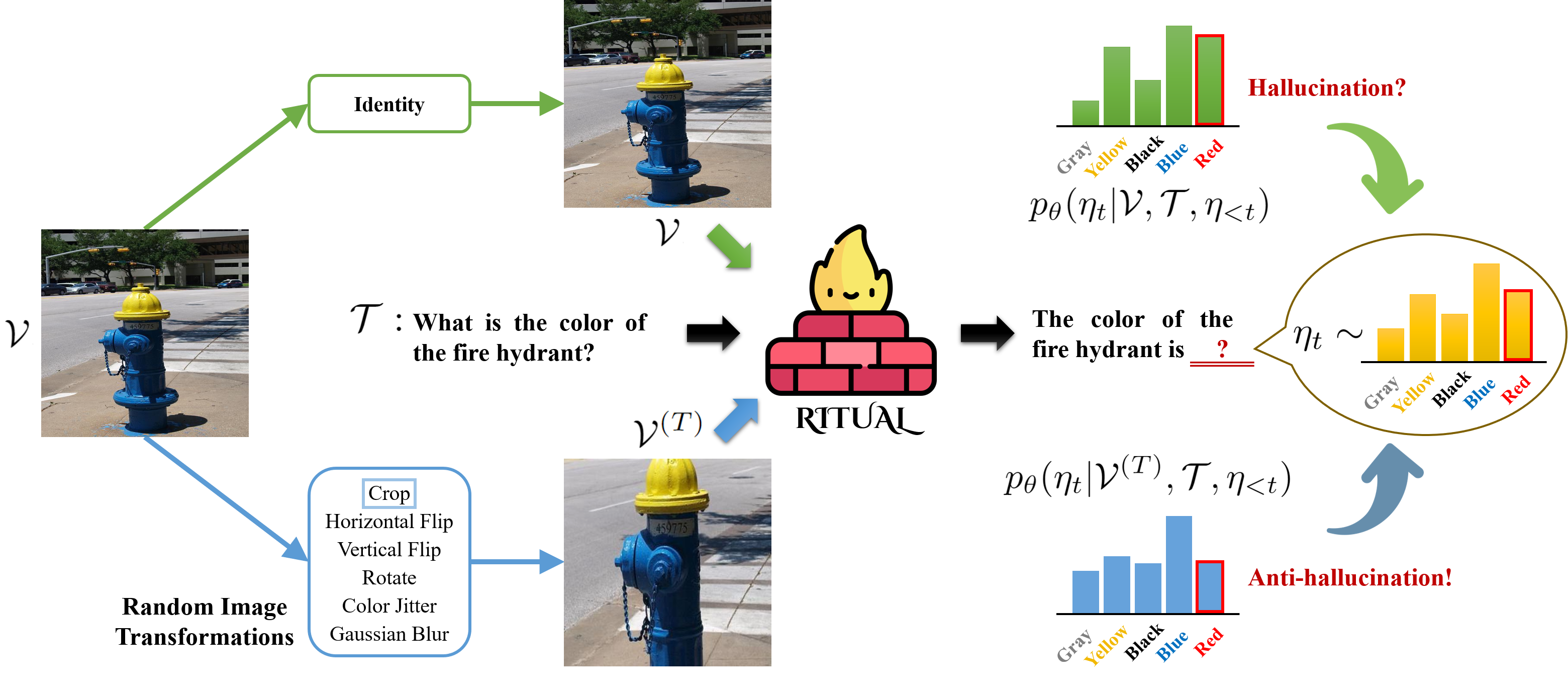
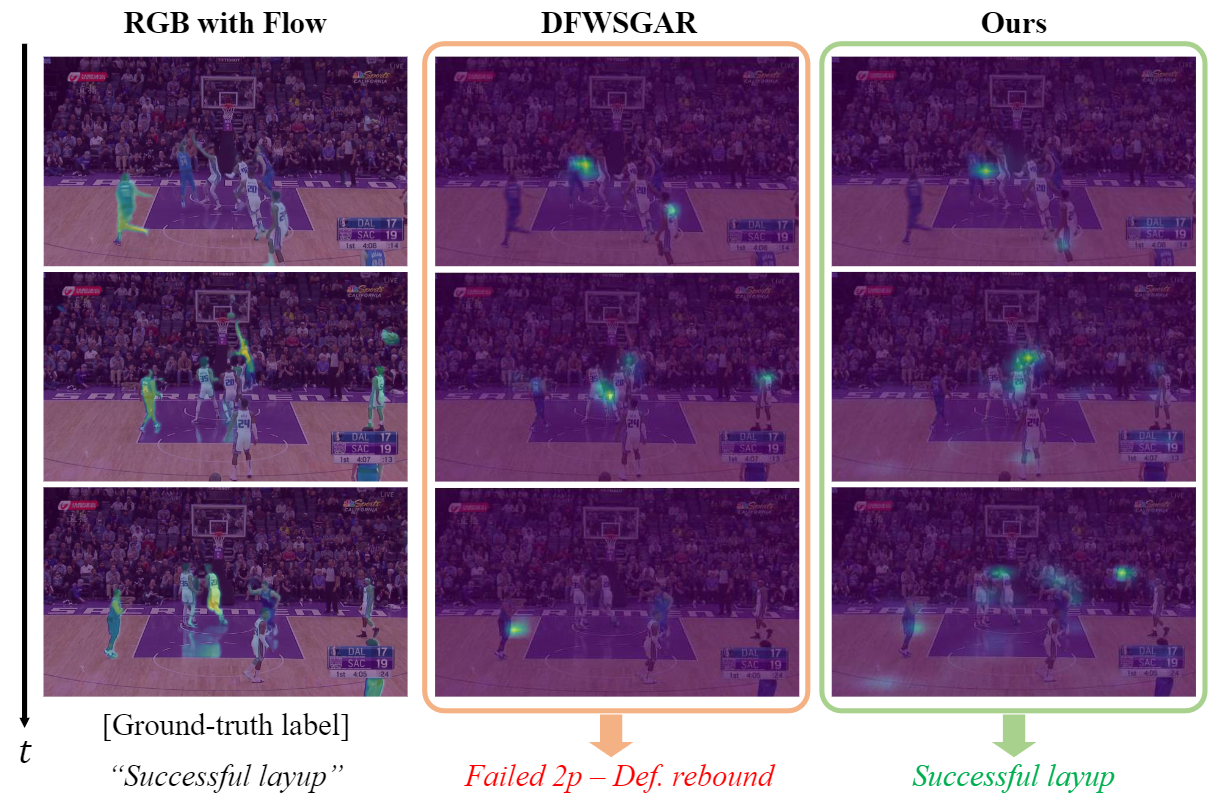
Sangmin Woo
Applied Scientist @ Amazon
Contact
-
sangminw [at] amazon.com
shmwoo9395 [at] gmail.com
-
2795 Augustine Dr, Santa Clara, CA 95054, United States
I am an Applied Scientist at Amazon Agentic AI. I received my Ph.D. degree at KAIST.
Humans are inherently multi-modal learners, naturally understanding the world by looking (vision), communicating & thinking (language), listening (audio), and interacting (action). I am passionate about advancing machine intelligence to mirror this ability, enabling systems to understand the world holistically.
My work explores the following, but not limited to:
- Multi-modal AI: Vision + {Language, Audio, Action, etc.} Multi-modal
- Generative AI (Vision Language Models, Large Language Models, Diffusion Models, etc.) Gen AI
- Agentic AI Agent | Visual Understanding Video Image
News
26.01 2 papers accepted to EACL 2026 (1 Main, 1 Findings)!
25.08 1 paper accepted to ESWA!
25.08 1 paper accepted to EMNLP 2025 Main!
25.06 I am starting my new chapter at Amazon! 🧑🏻💻
25.06 Selected as an Outstanding Reviewer at CVPR 2025!
25.05 1 paper accepted to ACL 2025 Findings!
25.05 Successfully defended my PhD! 🎓
25.04 1 paper accepted to CVIU!
25.02 1 paper accepted to CVPR 2025!
25.01 1 paper accepted to NAACL 2025 Main!
24.12 1 paper accepted to AAAI 2025!
24.09 Excited to keep collaborating with the team remotely!
24.09 I had a fantastic summer internship with Amazon!
24.07 3 papers accepted to ECCV 2024!
24.06 I joined Amazon Bedrock as a summer intern!